Thoughts on 'Learning Mechanics'
Last month, I stumbled upon an optimistic-sounding paper: “There Will Be a Scientific Theory of Deep Learning”.
In this paper, we make the case that a scientific theory of deep learning is emerging. By this we mean a theory which characterizes important properties and statistics of the training process, hidden representations, final weights, and performance of neural networks.
Historically, machine learning has been a field where theoretical understanding has lagged far behind empirical success. This paper argues that might soon start to change. The authors propose that we are gradually seeing the emergence of what they call learning mechanics—a mathematical understanding of the process by which machine learning models learn. And the newly-developing theory looks an awful lot like physics!
We argue that the emerging theory is best thought of as a mechanics of the learning process, and suggest the name learning mechanics. We assert that learning mechanics should be a mathematical theory, grounded in first-principles calculations that closely predict empirics, reliant on well-tested approximations and assumptions, aiming for broad impact across the machine learning stack once it reaches maturity.
The name “learning mechanics” was deliberately chosen to echo the various mechanics of physics. Examples of mechanics are:
- Classical mechanics: the study of how objects move and interact under the influence of forces.
- Statistical mechanics: the study of how the collective behavior of many microscopic particles gives rise to macroscopic phenomena like temperature and pressure.
- Quantum mechanics: the study of how matter and energy behave at the smallest scales, where physical quantities are quantized and governed by probabilistic laws.
Taken together, these bodies of work share certain broad traits: they are concerned with the dynamics of the training process; they primarily seek to describe coarse aggregate statistics; and they emphasize falsifiable quantitative predictions.
There is a clear emphasis on the dynamics of the learning process. Others in machine learning share this perspective. For example, at the most recent NeurIPS, there was a DynaFront workshop focused on applications of dynamical systems theory to machine learning.
There is also a clear emphasis on the importance of empirics. Historically, many theoretical machine learning researchers have come from computer science backgrounds, where the research style is much closer to math than to physics: an emphasis on formal proofs and rigor. While rigor is valuable, there has perhaps been an underemphasis on mathematical models that, while not entirely rigorous by the standards of proof-based mathematics, are motivated by deep principles and can explain important, previously-unexplained aspects of real-world data.
The authors do offer a note of caution though: learning mechanics is not meant to be the be-all and end-all. They acknowledge that different levels of description will always be necessary. Just as we still need biology to understand the anatomy of organisms and psychology to usefully model human behavior, there will be analogous magisteria for understanding neural networks. They describe their approach as complementary to alternative perspectives like mechanistic interpretability.
We discuss the relationship between this mechanics perspective and other approaches for building a theory of deep learning, including the statistical and information-theoretic perspectives. In particular, we anticipate a symbiotic and mutually supportive relationship between learning mechanics and the developing discipline of mechanistic interpretability. Where mechanistic interpretability aims to be the biology of deep learning, learning mechanics should aspire to be its physics, mirroring the complementary relationship between biology and physics in the natural sciences.
Putting my cards on the table: I really like the framing of learning mechanics. My current work falls squarely under the umbrella they describe. The idea that my research is not an isolated effort but part of the broader emergence of something as estimable as a Learning Mechanics™ seems tailored to flatter my biases.
In addition to releasing the paper, the authors launched a website which features essays that build up the learning mechanics framework. There is also a podcast episode where Jamie Simon and Daniel Kunin, the two lead co-authors of the paper, discuss the ideas it touches on.
The Five Approaches
One could ask: Why should we think a theory of deep learning is even possible?
A great cause for optimism that a mechanics of learning is possible is the fact that the essential ingredients of deep learning are both explicit and measurable.
Nothing about the learning process is hidden. Unlike many complex systems where the equations governing dynamics must be inferred from observations, deep learning directly exposes its “equations of motion.” Moreover, these dynamics are extraordinarily measurable: every weight, activation, gradient, and loss value can be recorded, along with arbitrary statistics derived from them. As a result, deep learning experiments are unusually easy to design, replicate, and interrogate, making it more straightforward to discover empirical regularities and rigorously test theoretical predictions. Few fast-moving scientific domains offer comparable transparency in their governing equations or comparable freedom in what can be measured.
In many ways, deep learning is the opposite of physics. In physics, we typically discover the limiting cases before we discover the more general underlying laws. For example, we first deduced $F = ma$ before we discovered special relativity—and it was only after the discovery of special relativity that we realized Newton’s second law is not fundamental, but corresponds to the infinite-speed-of-light limit of four-momentum dynamics.
This seems like a cause for optimism! Imagine how much harder deep learning would be if we only had access to the trajectories of the weights—and if our measurements were noisy or we couldn’t measure all the parameters all at once.
I would contend that, in deep learning, we already know the fundamental laws. While one could argue that gradient descent has to be computationally implemented on a computer, which could be considered another microscopic level underneath, in practice we can ignore this—it doesn’t affect the dynamics in any meaningful way. The lowest-level, microscopic description is known to us.
Given all of this, why don’t we already have a theory of deep learning?
The central challenge is not opacity, but complexity. While we have direct access to the architecture, data, task, and learning rule, the interaction of these components gives rise to learning dynamics that are nonlinear, coupled, and high-dimensional. These dynamics depend in subtle ways on the choice of hyperparameters. And even though we can inspect every training sample, data distributions are complex and have defied simple characterization.
Despite the complexity, they identify five major strands of evidence for the emergence of learning mechanics:
- solvable idealized settings that provide intuition for learning dynamics in realistic systems;
- tractable limits that reveal insights into fundamental learning phenomena;
- simple mathematical laws that capture important macroscopic observables;
- theories of hyperparameters that disentangle them from the rest of the training process, leaving simpler systems behind; and
- universal behaviors shared across systems and settings which clarify which phenomena call for explanation.
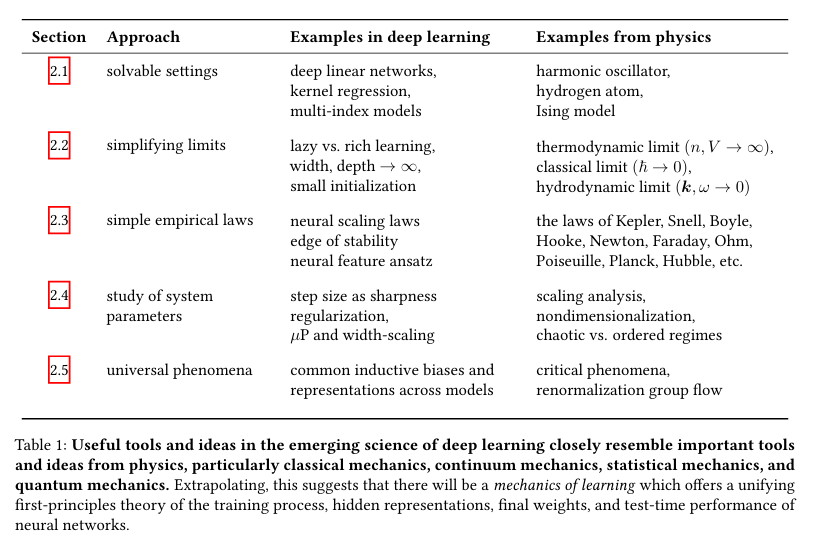
It’s worth emphasizing the physics-flavoring of these strands.
Physics is famous for its creative and ubiquitous use of toy models, which it then uses to build intuition for more complex phenomena. For example, consider the harmonic oscillator. I first learned about harmonic oscillators all the way back in high school, when we studied pendulums swinging back and forth. I would then encounter them again and again as I took progressively harder physics classes. In electromagnetism, the modes of the electromagnetic field in a cavity behave as a collection of harmonic oscillators. And in quantum field theory, free field theory is set up as an infinite collection of quantum harmonic oscillators.
Similarly, physicists are famous for their use of limits. The idea is that if you understand the behavior of a system in various limits, you can “interpolate” between them and understand the broader behavior of the system. For example, suppose you are studying how objects fall under the influence of air resistance, and I give you this formula:
\[\frac{dv}{dt} = -g - \frac{k}{\rho} v\]where $v$ is the vertical component of the velocity (with up being positive), $g$ is the gravitational acceleration, $\rho$ is the mass density of the object, and $k$ is a constant that depends on the size and shape of the object and the properties of the surrounding air. How would you check the plausibility of this formula?
One way is to check its behavior in various limits. Let’s hold the size and shape of the object fixed. In the limit where the density goes to infinity, the drag term vanishes and the object falls under gravity alone. That makes sense: if you drop a rock off a building, it falls like, well, a rock. In the opposite limit, where the density goes to zero, the drag term dominates and the object barely accelerates. That also makes sense: if you drop a beach ball off a building, it drifts down slowly rather than plummeting.
Checking the limits of a theory can be especially useful when doing research where there is no answer key: you can save a lot of time by discarding working hypotheses that give the wrong answer in relevant limits. (Though of course there is an art to this. You have to be correct about which limiting behaviors are the relevant ones—which can be tricky.)
The theory of hyperparameters is a bit subtler to interpret through the physics-inspired lens. Why would it be important to “disentangle” hyperparameters like learning rate and batch size from each other? What is the analogous principle from physics? I would argue that it has to do with ontology—what the fundamental objects of your theory are. When you are working in the right ontology, the core quantities are often interpretable and intuitive. And getting the ontology right is often a precursor to making deep progress.
One of the philosophical subtleties of physics that was important for me to internalize early on in my journey was that equations and theorems in physics shouldn’t be interpreted as mere tautologies. The quantities on opposite sides of an equals sign often carry an intuitive, folk-physical meaning that are independent of the physical law. And that matters because beautiful physical theories aren’t just mathematically true—they also carry important implications for how we should physically interpret the world.
Take Newton’s second law as a famous example:
\[F = ma\]The reason this is a deep theory is that all three quantities have an intuitive, independent meaning. Force is the “interaction” that causes things to move. Mass is how much stuff there is. Acceleration is how quickly your velocity is changing. That they are connected in exactly this way matters: the world would look quite different if $F = mv$. The formula needs to take precisely this form for it to be Galilean invariant—the same for all inertial observers who differ only in their relative velocity.
I’m no historian of physics, but my impression is that a lot of subtle progress comes from getting the interpretation right, not just the math. Take special relativity: much of the mathematical machinery was already present in the work of Lorentz and Poincaré. But Einstein gave it the correct physical interpretation—understanding length contraction and time dilation not as dynamical effects of motion through an ether, but as consequences of the nature of space and time themselves. That conceptual reframing was arguably what made the leap to general relativity possible. In that vein, having a theory of hyperparameters that can be cleanly disentangled from the rest of training seems to suggest that we are converging on the right ontology for the optimization dynamics. We can alter the relevant hyperparameters and have a principled, heuristic understanding of what will happen when we do.
Lastly, they invoke the concept of “universality”—which is important in two slightly distinct ways.
Universality implies a consistent underlying cause, which is what allows us to even hope for a scientific theory in the first place. In physics, we observe that if you drop an apple in New York City and drop an apple in Paris, they fall at roughly the same rate. That they fall at the same rate probably isn’t a coincidence—it’s the product of a deeper law governing the behavior of both apples, even though they are separated in space and time. In neural networks, the fact that many different architectures are capable of learning the training data and converging on similar learned functions (implying similar inductive biases) suggests that even though machine learning models appear to be black boxes, their complexity is not irreducible.
The other notion of universality is evocative of statistical physics. With renormalization, universality says that as you coarse-grain, the microscopic details wash away, and systems that superficially look different end up behaving similarly. The classic example is the Ising model and the liquid-gas transition. While magnets and water may seem like very different systems, you can show that near the critical point they behave quite similarly (the rough intuition being that the liquid phase is like being spin-up and the gas phase is like being spin-down). You also see universality in random matrix theory. A random matrix is a matrix where each entry is a random variable. In the thermodynamic limit (as the size of the matrix goes to infinity), many different distributions for the entries converge to the same ensemble. Just as in renormalization, microscopic details (like higher-order cumulants of the entry distribution) are washed out.
Open Directions
So where does learning mechanics go from here? At the end of the paper, the authors list ten open directions they believe the field needs to resolve to achieve its objectives:
- Open Direction 1: What are simple, solvable models of genuinely deep, nonlinear learning?
- Open Direction 2: What would a theory capable of capturing natural data look like?
- Open Direction 3: Does deep learning implicitly minimize some notion of functional complexity?
- Open Direction 4: How do we formally define the features learned by neural networks?
- Open Direction 5: Are finite neural networks properly understood as approximations to infinite limits?
- Open Direction 6: Can we understand and eliminate all hyperparameters?
- Open Direction 7: Can we predict scaling law exponents a priori?
- Open Direction 8: How does loss curvature interplay with architecture, features, and generalization?
- Open Direction 9: What makes for a good optimizer in deep learning?
- Open Direction 10: In what sense do large models trained differently learn similar representations?
Open Direction 2 is the one that I find interesting, though I’m not sure how to make progress on it. There’s a contingent in machine learning that argues that because deep learning works reasonably well across different architectures and learning algorithms, the “secret” must lie in the data itself: there must be some property of real-world data that makes it efficiently learnable. Ideas in this vein include the manifold hypothesis—that data lives on a lower-dimensional manifold. However, I have yet to encounter a “theory of data” that I find to be satisfying.
The closest line of research I know of to formulating a theory of data is the single-index model literature. A single-index model is a class of functions where, given some random input $x$, the output is computed by (1) projecting the data onto a direction $w$, and (2) passing the result through a non-linearity:
\[f(x) = \sigma(w \cdot x)\]The idea is that modeling the true underlying function as a projection composed with a non-linearity captures the notion that data has only a few relevant directions. Researchers have shown, for example, how the choice of non-linearity affects the difficulty of recovering those relevant directions.
Open Direction 7 would also be nice to resolve. Being able to predict scaling laws from theory would be valuable—not because the precise numerical value of the exponents themselves matter so much, but because a scaling exponent is a single concrete number that must integrate everything about the data, architecture, and training algorithm. Predicting it correctly would suggest we’ve landed on the right conceptual framework for understanding machine learning.
Being able to calculate scaling exponents from first principles would also be interesting because it might shed light on deeper conceptual questions. For example, there is a perspective that even though the loss curve looks smooth and continuous, what’s actually happening under the hood is a series of small discrete jumps—each shaped like a sigmoid—where the model abruptly learns some concrete capability. Being able to predict scaling exponents would help test this view and quantify the intuition, potentially connecting it to ideas like saddle-to-saddle dynamics.
Open Direction 9—what makes for a good optimizer?—is something I’ve been pondering a lot lately. At this point, I feel like I have a pretty good grasp on what optimizers like stochastic gradient descent and Adam actually do from a dynamical perspective, and how that hashes out in terms of affecting quantities like the sharpness. But I don’t quite understand how it all connects to core questions like: Why do neural networks generalize? Why do some optimizers generalize better than others? I’ve always been suspicious of the flatness-equals-better-generalization story. My guess is that once we figure out what’s really going on, we’ll realize flatness was a proxy for some more fundamental, abstract property of the learned solution. And that optimizers preferring flat solutions will, as a by-product, also prefer that abstract property.