Thoughts on OpenAI o3
Remember how, when discussing my personal rankings of LLMs, I said “The best [LLM]—honestly, by far—is Claude.”
Well, Sam Altman seems to have taken that little remark personally.
A couple of days ago, OpenAI announced their latest model, OpenAI o3. (Their previous best model was o1, but they claimed to skip o2 due to copyright concerns.) I can’t find an official announcement from them as they did with previous models like GPT-4. Various news sources—TechCrunch, Wired, and New Scientist—are all reporting the same impressive claimed performance of o3 on various standard benchmarks. The best and most comprehensive source I could find was Francois Challet’s (a famous ML engineer, formerly at Google) description of how o3 did on the ARC-AGI-1.
ARC-AGI-1 is a test meant to evaluate the performance of AI models. The questions are composed of visual puzzles like this one:
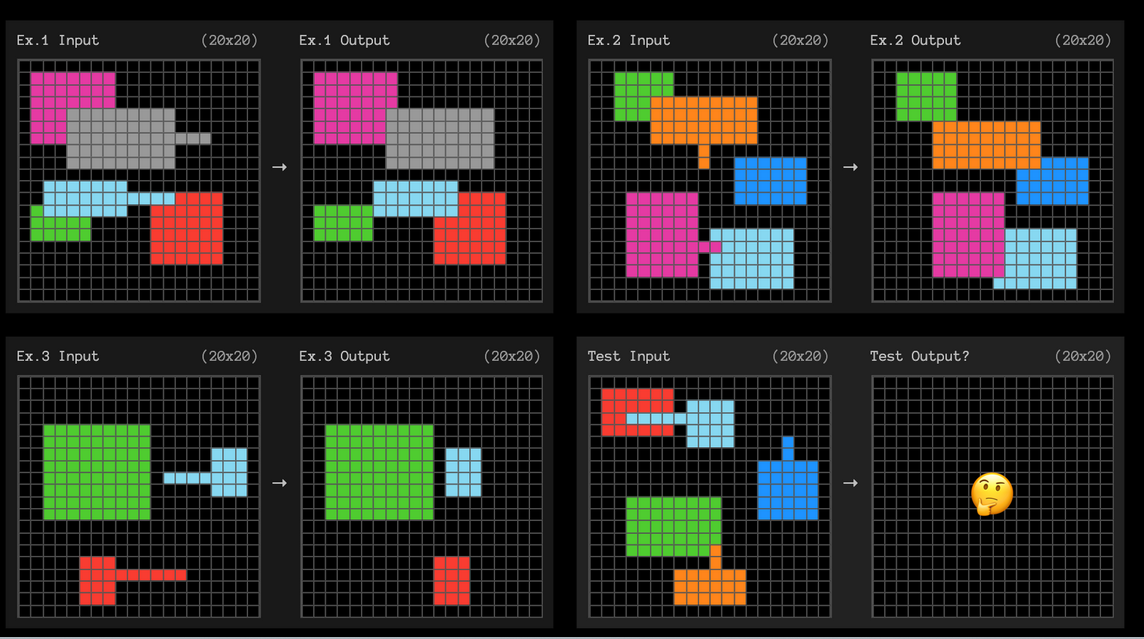
You might be wondering why we would be interested in how LLMs perform on such strange-looking problems. It’s because increasingly what we care about is not an LLM’s ability to recall information (e.g., “Who was the first president of the United States?”), but rather its ability to solve completely novel intellectual tasks that weren’t represented in the training data. To do that, you need to devise problems that don’t overlap with standard school curricula, which are heavily represented in the training data that LLMs learn from (i.e., all of the Internet).
In ARC-AGI-1, there are two sets of problems: public problems and semi-private problems. Public problems are freely available—and, in fact, OpenAI trained o3 on 75% of the problems in the public dataset. The semi-private problems are problems that are withheld from the training data—which gives a better measure of the true capability of the model since it can’t resort to memorization. (In what sense it’s “semi-private” versus “private”, I’m not sure.)
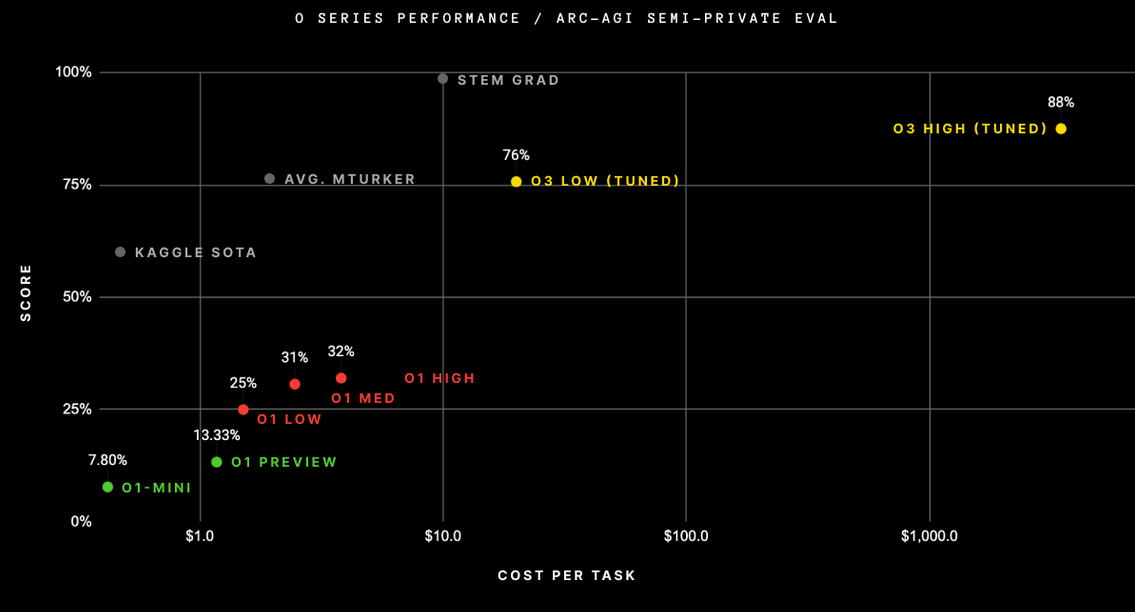
According to the report, the o3 model achieved remarkable results under different compute constraints. When restricted to spending only $10,000 on compute costs, o3 performed at 75.7% on the semi-private evaluation. When allowed to use 172x more compute—spending over one and a half million dollars—the model’s performance jumped to 88% on these problems. These marks far eclipse the previous best performance of o1.
However, there’s an important caveat about these results. While the semi-private problems were indeed withheld from the training set, the fact that o3 trained on 75% of the public problems raises some concerns. If the problems in the semi-private set are structurally similar to those in the public set, the model might be benefiting from indirect exposure to similar problem-solving patterns, even if it hasn’t seen the exact problems before.
There is a phenomenon called Goodhart’s law. It states that when a proxy is used as a target metric, it ceases to be a good proxy as people will optimize for it directly. For example, imagine you run a company and internal data analysis shows a strong correlation between employees arriving early and their measured productivity. If you then make arriving early an explicit standard, people will simply show up early and spend the first hour browsing reddit—meaning early arrival is no longer a reliable signal of a productive employee.
Because of these dynamics, I am increasingly suspicious of AI benchmarks. As competition intensifies, AI companies have strong incentives to optimize their models specifically for leading benchmarks, rather than for the broader space of useful intellectual tasks that we actually care about.
There’s another important issue to consider. Superficially, the jump from 32% to 76% sounds dramatic—more than doubling the score! But it’s not clear how meaningful this improvement is. Let me explain with an analogy.
Imagine two different math tests. The first test only covers one concept: calculating the area of circles. The questions might vary—find the area given the radius, find the radius given the area, or if the test is feeling particularly frisky, find the area given the diameter—but they all test the same basic skill. On this type of test, you’d expect scores to be strongly clustered near either zero or 100%. Either you know the formula and can apply it, or you don’t. In terms of overall mathematical ability, this test isn’t very informative. A student could go from 0% to 100% in ten minutes simply by learning one formula and doing a few practice problems.
Now imagine a different test—a comprehensive math assessment covering the entire high school curriculum: algebra, trigonometry, geometry, pre-calculus, and calculus. On that test, going from 0% to 100% would be enormous. It would represent the intellectual progress that a bright high school student achieves over four years of schooling.
So which type is the ARC-AGI-1 test? Is it more like the circle area test, or more like the comprehensive high school exam? This distinction matters if we want to properly interpret what the raw jump in percentage scores actually means.
In any case, a new version called ARC-AGI-2 is in development, and they claim (based on private testing, I assume) that even o3 struggles with it. They’ve reportedly been developing ARC-AGI-2 since 2022—for reference, that’s when ChatGPT kicked off the modern commercial age of LLMs. This long development timeline suggests they’ve been carefully considering all the key challenges: Goodhart’s law, training data contamination, and the need to cover a wide range of ability levels when constructing their new benchmark test.
Regardless of o3’s capabilities, the model isn’t economically viable yet. Running each task costs around $20. However, prices in AI have consistently dropped quickly, whether through improved manufacturing or cleverer algorithms, so I doubt this cost will remain a barrier to commercial use for long.
While OpenAI has been fairly reticent (for understandable reasons) about releasing technical details behind o3’s improved performance, we do know something about how it works. The model first constructs a prompt (“natural language instructions”) and then executes that prompt to try solving the problem. This prompt construction process is guided by reinforcement learning.
This represents a different kind of progress than what has driven LLM advances for the past couple of years. The previous paradigm relied on scaling laws—the idea that performance primarily depends on compute, which is the product of the model’s parameters multiplied by the training data size. But murmurings suggest this approach is no longer sufficient, and top companies are looking elsewhere to squeeze more capability out of their models.
What’s particularly interesting is that they’re performing guided search over the space of programs—something akin to human thought processes. Normal LLM reasoning is essentially stream-of-consciousness (albeit an unusually refined and articulate one). With the ability to “think” before “speaking,” it makes sense that new capabilities would emerge. However, I’m not sure if this is the most elegant approach. The article mentions that one could perform program search in “latent space,” which seems closer to how humans actually think. After all, some people don’t have internal monologues, yet they still manage to execute long-term plans—from showing up to doctor appointments to founding companies.
Beyond ARC-AGI, the model’s performance on FrontierMath has also been generating buzz. While the ARC-AGI results raise questions about benchmark reliability, the FrontierMath results seem even more impressive at first glance—though again, I’m not sure to what extent OpenAI trained on this dataset.

FrontierMath is a compendium of math questions, ranging from high-level competition math to research-level problems. Rather than testing general reasoning like ARC-AGI, these problems are designed to challenge even expert mathematicians.
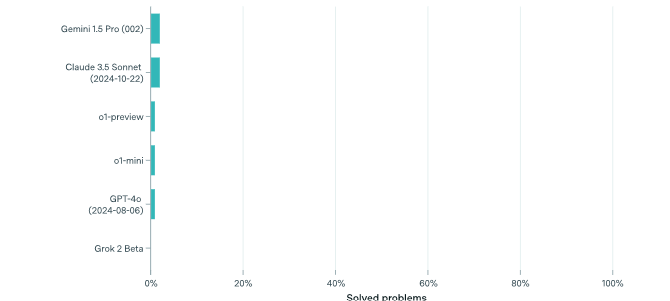
While previous models answered approximately 0% of the questions, o3 managed to solve 25% of the problems they tested it on.
However, there’s an important caveat: the questions the model answered weren’t the difficult research-level problems requiring novel insights, but rather the more standard questions that—while too hard for 99.9% of people—are represented in the training data through graduate-level math textbooks. This means the achievement, while impressive, isn’t qualitatively different from the problem-solving abilities that models have demonstrated in other contexts.
Alright, I’ll stop beating around the bush: Is o3 AGI?
Probably not. Even ARC-AGI’s press release (which is clearly partial to o3) pushes back against any premature coronations of the model as AGI. And my personal biases make me skeptical of OpenAI hype at this point. Compared to rival companies like Anthropic, OpenAI is the most nakedly corporate, the most gung-ho about “winning” the AGI race. Given the increasingly huge capital requirements for training these large language models, they have strong incentive to maintain a narrative of being in the lead at all times. This explains why, over the past two years, they’ve continually released improved versions of their models and advertised them widely.
In any case, they’ve announced that after some initial “safety testing,” they’ll release the model to the public in January. If it’s reasonably priced (around $20 per month), I’ll test it out and form my own opinion. If it’s exorbitantly priced (which seems more likely), I’ll have to defer to others’ assessments.